模型参数放在flash,按需带入DRAM。
效果
可以跑的模型大小是DRAM的2倍,推理速度提高4-5倍(cpu), 20-25倍(gpu)
方法
- 减少数据传输
- 读flash的时候读更大更连续的块来加快从 flash 到 dram 的速度
第一块:减少数据传输主要有几个点,按照从flash到dram的顺序写
1. 第一步:加载啥
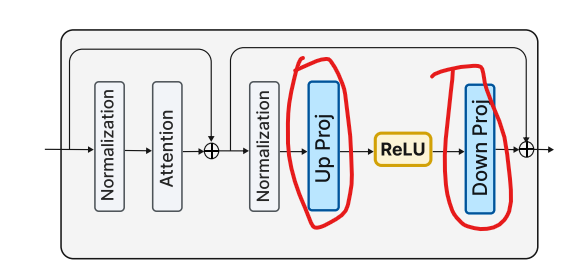
减少的是ffn神经元里边参数的传输(下边红圈,这里我没太懂 up projection 和 down projection)。
对于attention部分和embedding部分省不了,还是会全放进dram,约占总模型大小的三分之一。
2. 第二步:神经元参数怎么选择性加载
根据的是apple之前的另一个论文ReLU Strikes Back,主要就是说模型的稀疏性,在模型使用的时候实际90%以上的神经元都没用到,就像说人脑只开发了5%一个意思,也不知道谁统计的。
基于这种稀疏性,论文就提出那别全加载了,太浪费了,选择性加载吧。这一下就不少很多么。

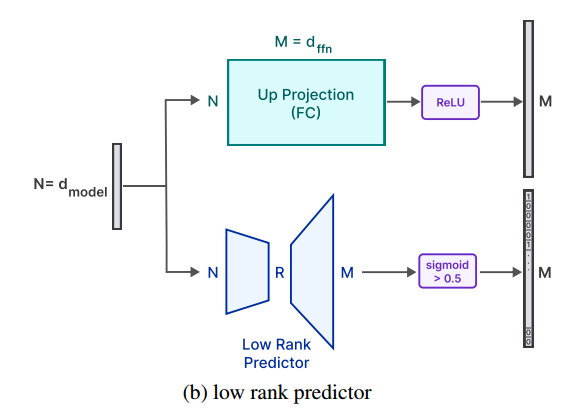
那怎么选择加载谁呢,他们建了一个predictor,方法是通过低秩矩阵,如下图,没具体说怎么做出来的predictor,猜测就是通过低秩来找到几个影响力大的。有了这个predictor,就能把输出是 0 的神经元排除了,不用加载了。
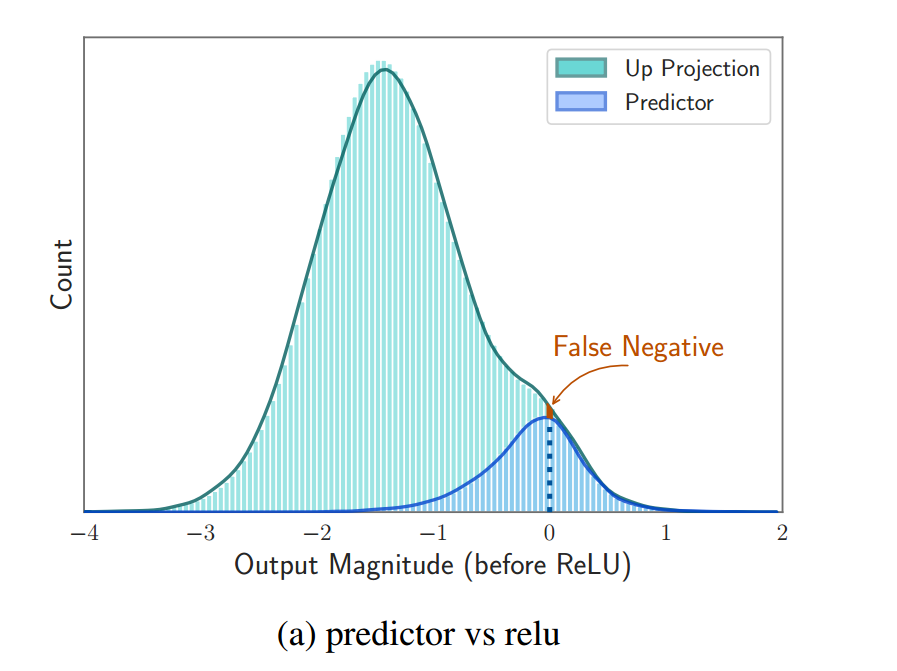
然后讲了 predictor 的准确性,如下图,正的负的预测都很牛,不准的地方只有竖轴那么一点点(你得放大了看),逆天。
3. 第三步:滑动窗口
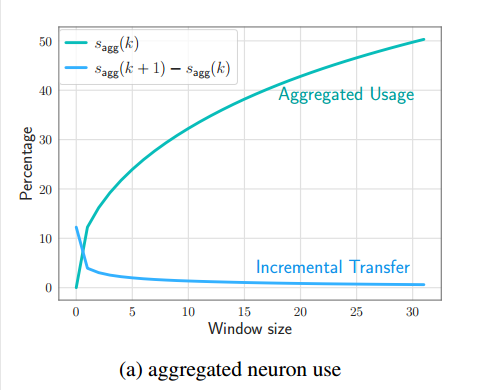
在LLM生成的过程中,他们做了一个驻留dram的token数的图,下边,意思就是说虽然随着token的生成,使用到的神经元的参数会越来越多(上边那条线),但是后一个token用到的参数相对于前边的token用到的所有参数来说增加的不多。看下图,比如在dram中驻留30个token的神经元参数(假设参数量为总参数量的50%,假设是35亿吧),那生成第31个token的时候,基本不需要新增参数了(新增接近 0%了都,可能总参数还是35亿多个一千两千的)
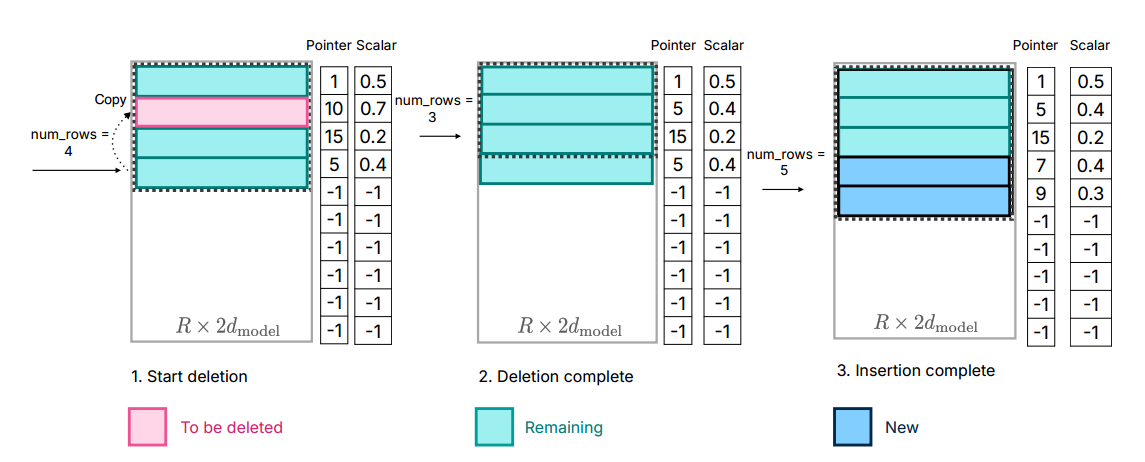
4. 第四步:在内存里也少倒腾
就是下边这个图,他说在内存里如果要删除不用的神经元参数的话,不要删掉后把后边整体往前移动,直接把最后边的参数覆盖那个要被删除的,要新增的话直接放到最后,然后修改指针地址,num_rows 增大。这样内存里倒腾的次数就少了。
第二块:从flash往内存读的时候读大块,比小块 快
他说从flash读小块,很多时间都花在数据传输开始上(latency to first byte),提倡读大块,即使读的时候包含一些没用的然后再丢弃也比读小块更快。大块和他最开始说的把少量东西放在内存相抵触,所以他说得trade off一下,既读大块,又尽量保证读的都有用,别无故撑大了内存。
这里提了两个方法读更大的块。
-
行列绑定(可用)
就像下图里边up proj 和 down proj,实际up proj 矩阵的一列经过 ReLU之后又要乘以 down proj的一行(这里应该是转置了,和论文里提到的行列颠倒了),所以论文里说可以把 up proj 的列和 down proj 的行拼在一起,一块读进内存,这样读的块就大了,计算的时候从中间一劈开就行了。
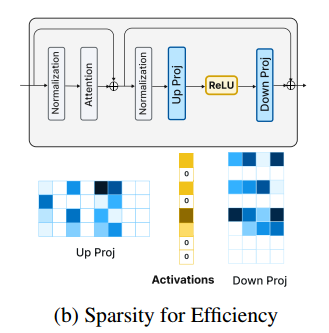
-
共激活(证明不行,写在论文里他们说因为这个研究挺有意思,可能以后会有新发现)
共激活就是他们发现神经元也有战友,就是往往激活的神经元都是有小团体的,一个被激活,他的亲近的朋友们也会被激活,所以他们就试图在从flash加载到内存的时候,如果加载了一个神经元,那么就把和他亲密的打包全加载进来,就相当于预判其他神经元也会被用到,实际也算是个predictor了吧。
但是发现这样不行,因为有的神经元太牛逼了,和谁都是亲密朋友,每次都有它。这样内存大小就降低不了了相当于。然后就没用。
问题:
- 现在说神经元利用率低,有提出把LLM也分module的,而且证明几个module配合,少参数模型也能达到多参数模型同样效果,少参数的模型不知道是不是也这么稀疏(超过90%没激活)。
- 既然模型90%都没激活,能不能生成模型的时候就把这90%全砍掉,即使可能损失一点模型能力,那使用起来模型岂不是大大缩小了么。