注意力的目标是用来更新词的具体意义。通过所有注意力模块的更新,使最后一个词(要生成的前一个词)包含远超单个词的信息量。
GPT-3
- 参数:176B (175,181,291,520)
- 矩阵:27,938
- Embedding维度:12,288
- vocab:50,257
Embedding:d_embed(12,288) * n_vocab(50,257) = 617,558,016
Unembedding:n_vocab * d_embed = 617,558,016
Embedding + Unembedding = 1,235,116,032
线性变换复合
多个矩阵与输入向量相乘的过程实际就是不断靠基向量的变换不断拉扯来拟合的过程。
指数函数
GenAI的目标输出是下一个 token 的概率分布,而本身矩阵向量相乘的结果可以是任意数,这就需要找到一个函数,它满足:
- 定义域是任意实数
- 值域大于 0 (为了计算概率)
- 增函数 (保证原输出结果的顺序)
由此引入了指数函数 – 原输出 x1 的概率可以表示为:e^x1/(e^x1 +e^x2+…+e^xn)
Temperature
因为指数函数是个增函数,所以值域的分布和定义域并不是均匀的,而是输入越大导数越大,增长越快。这导致不公平,输入值只大一点,输出概率却大很多。为了缓解,引入超参数 T,使概率计算变成 e^(x1/T)/(e^(x1/T) +e^(x2/T)+…+e^(xn/T))。
T 越大,会把输出值向左移动,缩小差别;T 越小,会向右移动,增大差别,使原来输入值大的概率更突出。
所以有些没有特殊处理的模型在设置 T是0时候会出错。
目标
一个词在最开始的时候向量是固定的,因为embeddings model是训练好的。 但是在不同的语境下意义会不同,注意力就是用来更新词的具体意义。
通过所有注意力模块的更新,使最后一个词(要生成的前一个词)包含远超单个词的信息量。
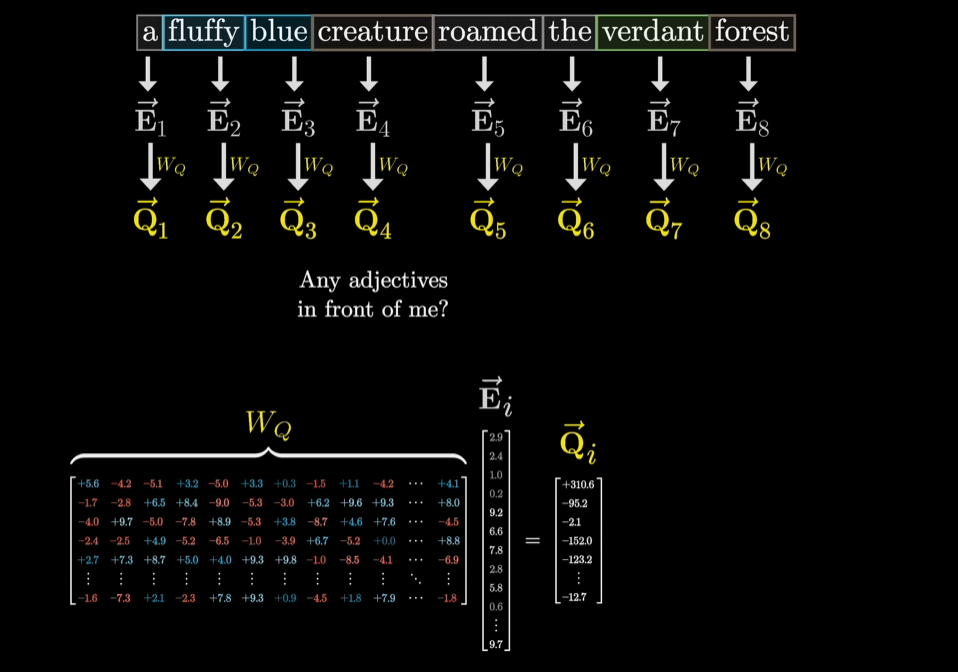
Query向量
每个词想知道其和前序词之间的关系(例如-只是举例,实际未必如此:我是一个名词,前面有没有形容词?),这就把原来12,288维的词向量变成另一个向量 - 查询向量。查询向量维度低很多,128维,即用一个在128维中的向量来编码 ”我前面有没有形容词?” 这个概念。
把词向量(12,288维)转换成查询向量(128维)需要一个矩阵(128x12,288)。(这个矩阵的数值都是模型的参数,从数据中学到的 — 这个矩阵在某个注意力头中的作用非常难以解释 — 乘就完了)
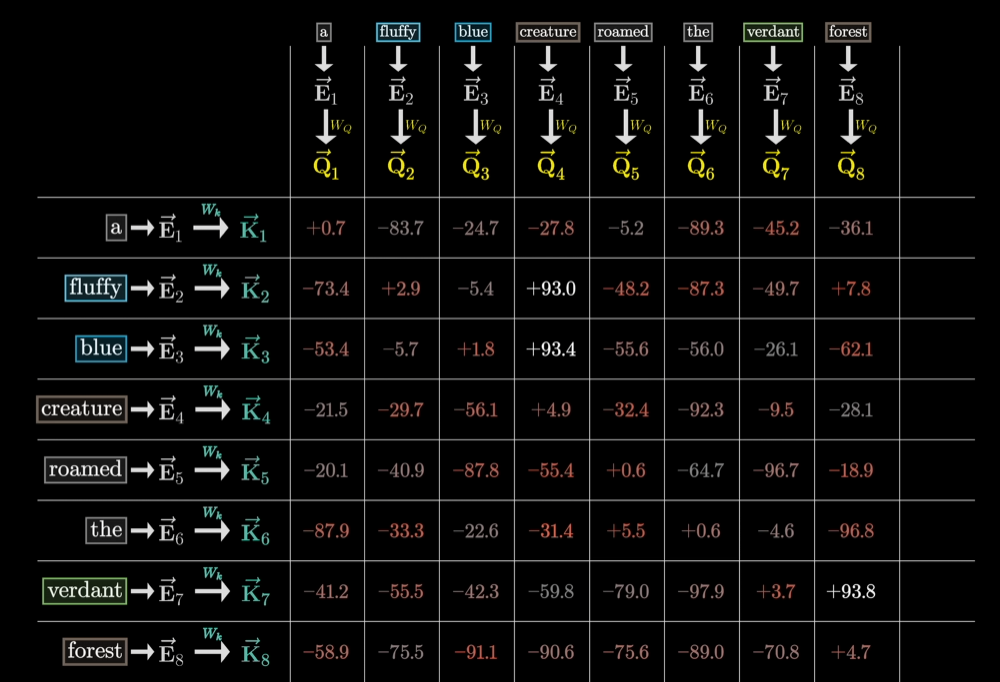
Key向量
可以看作是对于Query向量的回答向量,同样是128维,所以要词向量要乘以另外一个同样维度的矩阵(128x12,288),变换后的Key向量为128维,如果 Key 向量和 Query 向量在空间中的方向对齐,就认为它们匹配。
Key与Query的匹配程度
通过Key与Query之间的点积衡量,点积越大,Key与Query越对齐,越对齐(点积的数值大)就表示这个词与更新其他词的含义有多相关。
例如 ‘creature’ 问它前边的形容词有哪些(Query),’fluffy’ 和 ‘blue‘ 两个词的回答 (Key) 和 ‘creature’ 的Query最相关,所以点积最大。所以最后的点积的值,实际就是概率!但是因为点积可能有负值,所以和之前一样,用softmax (指数函数那个)。每列都softmax之后就得到 Key 与 Query 关联程度的概率值。这个概率的表格,就是注意力模式(attention pattern)。
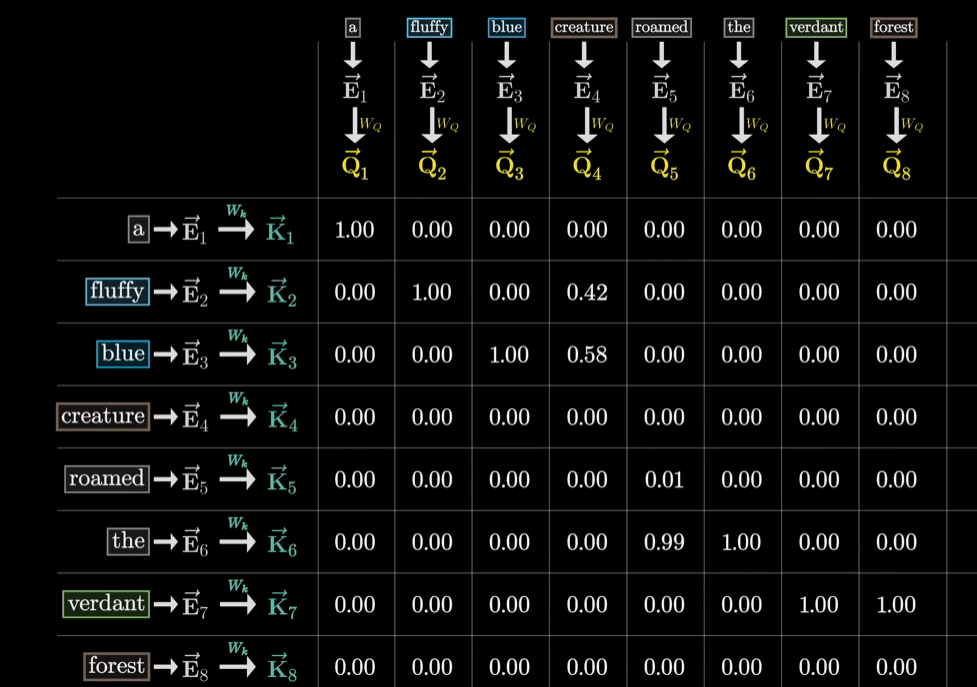
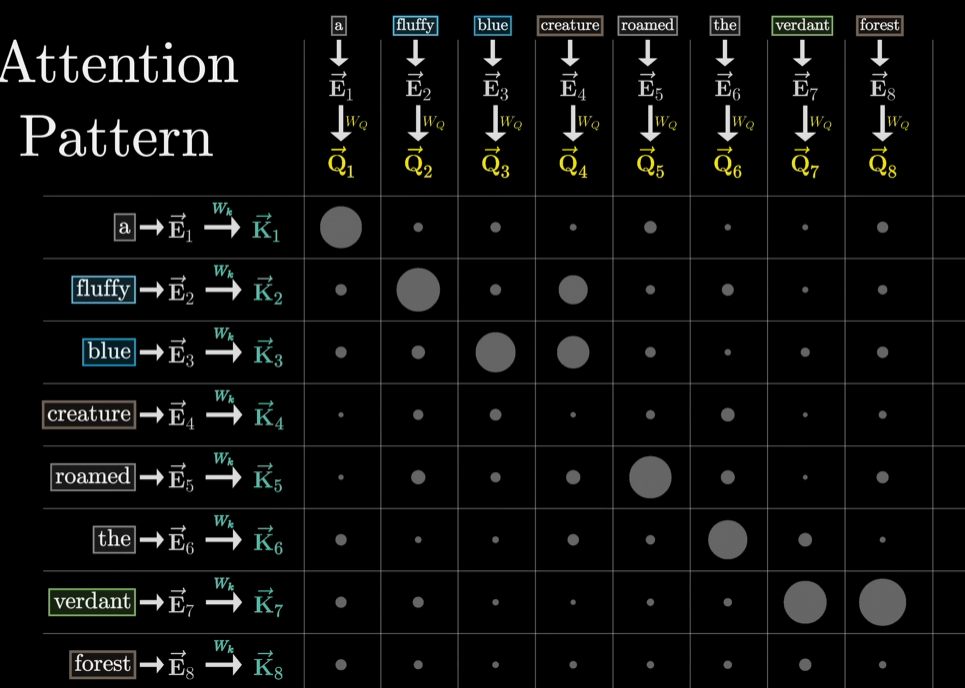
注意力模式的大小
每个输入的词(token)都会有一个 Query 和 Key向量,所以注意力模式的大小就取决于上下文长度的平方,所以上下文的长度会称为LLM的瓶颈。
V向量和变化向量
得到 Key 与 Query 匹配的概率,接下来要知道从当前词向量变化到新向量需要变动的地方,一个变化向量,即将当前词向量加上变化向量就等于新的包含更多信息的向量,那这个变化向量肯定要和原来的词向量维度一致(12,288)。
所以这次要乘的矩阵的维度就是 12,288 x 12,288。将每个词向量乘以该矩阵得到一个 V 向量,每个和上一步求出的 Key, Query 概率相乘再加和就得到了12,288维的变化向量。将原来的词向量加上变化向量,得到新的包含更多信息的词向量。

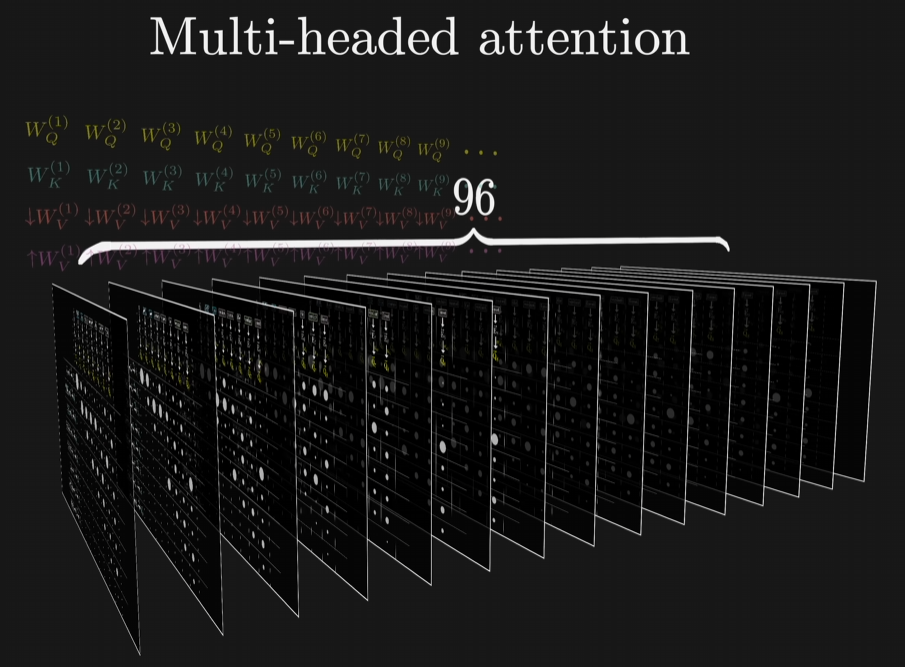
多头
上边就是单头的过程,多头就是每个头都有单独的 Query, Key 和 Value 矩阵。GPT-3每个模块内有96个注意力头。